1– ورود به دنیای Data Lakehouse
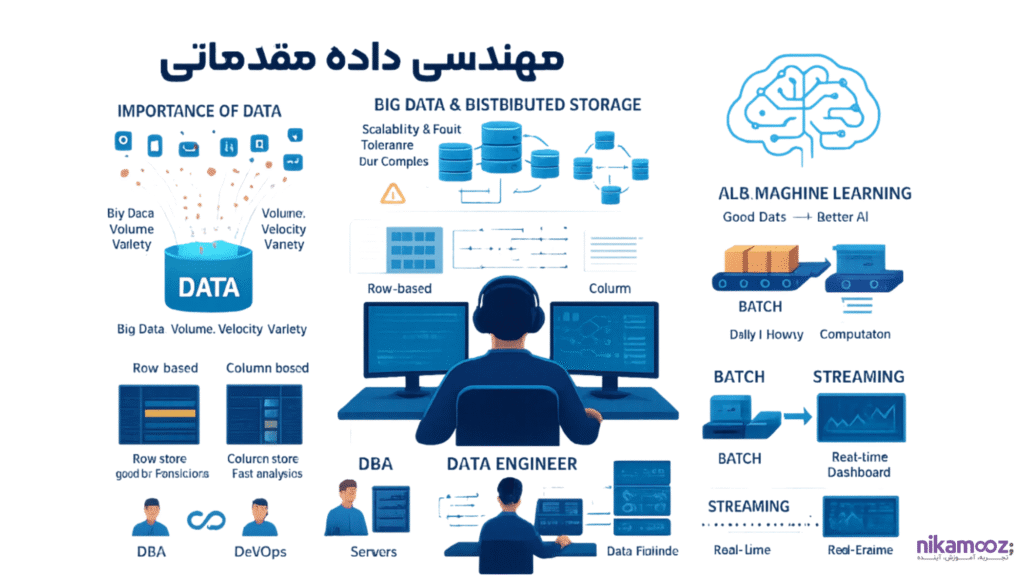
این فصل به عنوان دروازه ورود به دنیای مهندسی داده، اهمیت فزاینده دادههای حجیم و متنوع (بیگ دیتا) و چالشهای ناشی از ذخیرهسازی و پردازش آنها را بررسی میکند. در این بخش، شما با مسیر شغلی مهندس داده، تفاوتهای آن با نقشهایی مانند DBA و DevOps، و نقش حیاتی این تخصص در عصر هوش مصنوعی آشنا خواهید شد. همچنین، مفاهیم کلیدی مانند ذخیرهسازی و پردازش توزیعشده و مقایسه مدلهای ذخیرهسازی سطری و ستونی و مدلهای پردازشی Batch و Streaming به منظور ایجاد یک دیدگاه جامع از اکوسیستم دادههای مدرن، معرفی میشوند.
- مروری بر اهمیت داده، پایگاه داده و سیستم های ذخیره سازی
- مهمترین نیازمندی های لازم برای متخصصان مهندسی داده: مسیر حرفه ای شدن
- یک روز کاری مهندس داده چگونه است
- تفاوت ها و شباهت های نقش های مهندسی داده و DBA و DevOps
- عصر AI و اهمیت مهندسی داده
- بیگ دیتا چیست و چه کسانی بیگ دیتا دارند؟
- چالش های داده های حجیم و متنوع و بیگ دیتا
- ذخیره سازی توزیع شده، اهمیت و چالش های آن
- پردازش توزیع شده، اهمیت و چالش های آن
- مدل های ذخیره سازی سطری و ستونی و مثال هایی از آن
- مدل پردازشی Batch و Streaming
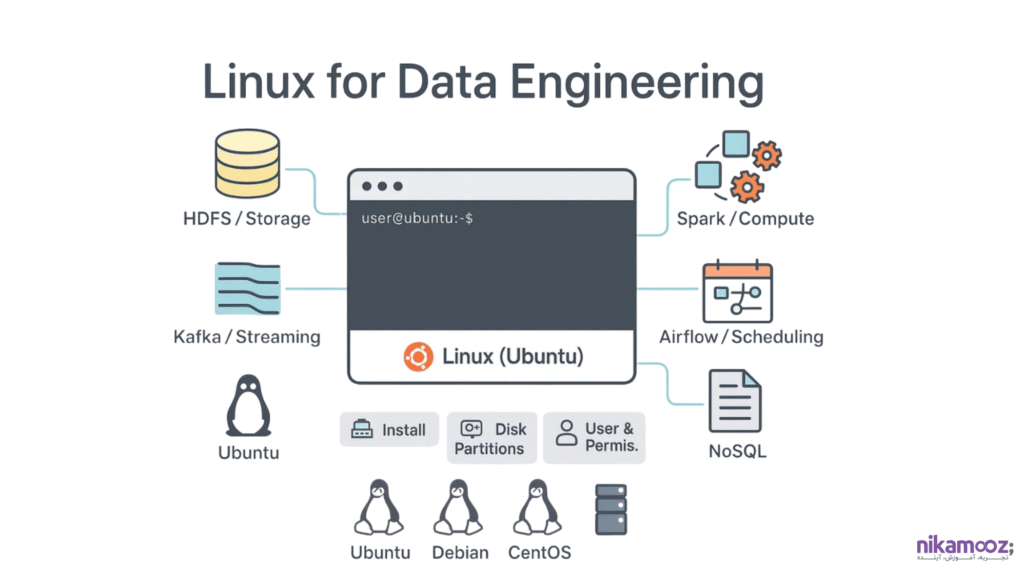
2– لینوکس برای مهندسان داده
از آنجایی که اغلب پلتفرمها و ابزارهای بیگ دیتا و پردازش توزیعشده بر روی سیستمعامل لینوکس اجرا میشوند، تسلط بر آن برای مهندسان داده ضروری است. این فصل اهمیت لینوکس را در زیرساختهای دادهای توضیح میدهد و بر روی مهمترین توزیعها (مانند اوبونتو) متمرکز میشود. شما مهارتهای عملی مورد نیاز برای کار با لینوکس، از جمله نصب، مدیریت اولیه توزیعهای مختلف، تنظیمات شبکه و درک مفاهیم پارتیشنبندی و مدیریت دیسک را برای آمادهسازی محیطهای کاری دادهمحور، فرا خواهید گرفت.
- اهمیت لینوکس
- توزیع های مهم لینوکس
- نصب و کار با Ubuntu
- مروری بر تنظیمات شبکه، پارتیشن بندی و دیسک
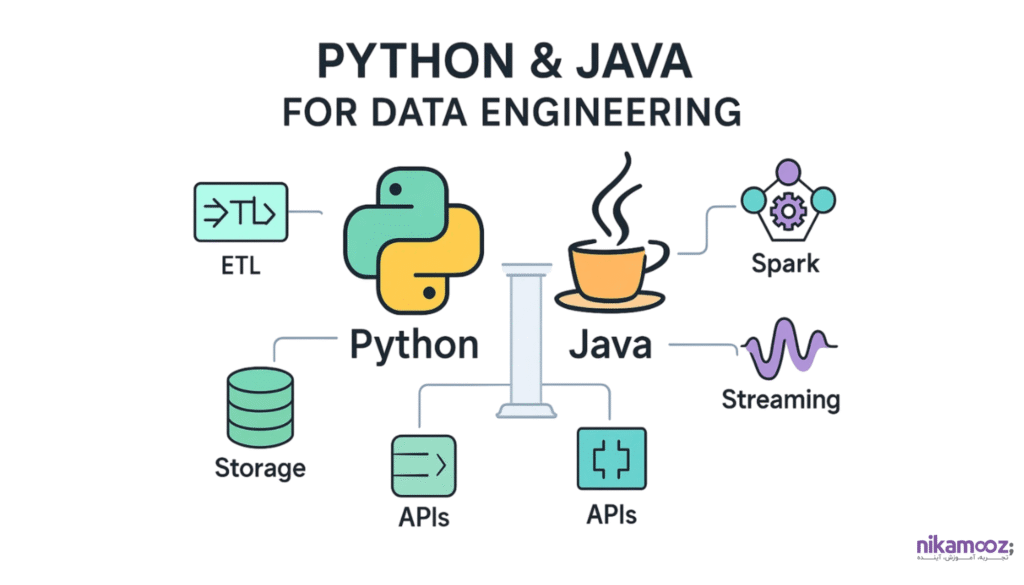
3–مقدمه ای بر جاوا و پایتون برای مهندسان داده
این سرفصل به معرفی و بررسی دو زبان برنامهنویسی پایتون و جاوا به عنوان ستونهای اصلی ابزارهای مهندسی داده میپردازد. این بخش بر تفاوت مهارتهای برنامهنویسی مورد نیاز مهندس داده در مقایسه با مهندس نرمافزار تأکید دارد، در حالی که نکات و اصطلاحات مهم طراحی نرمافزار را جهت توسعه کدهای پایدار و بهینه، آموزش میدهد. بخش عملی شامل کدنویسی و اجرای سناریوهای رایج پردازش داده با هر دو زبان و همچنین استفاده از گیت برای کنترل نسخه کدها و مدیریت پروژهها خواهد بود تا شرکتکنندگان آمادگی لازم برای کار با فریمورکهای مختلف دادهای را کسب کنند.
- زبان های برنامه نویسی مهم برای مهندسان داده
- آیا مهندس داده باید به خوبی یک مهندس نرم افزار در طراحی و برنامه نویسی باشد؟
- نکات و اصطلاحات مهم طراحی و توسعه نرم افزار برای مهندسان داده
- کار با گیت
- کد نویسی و انجام سناریوهای مختلف پردازش داده با پایتون
- کد نویسی و انجام سناریوهای مختلف پردازش داده با جاوا
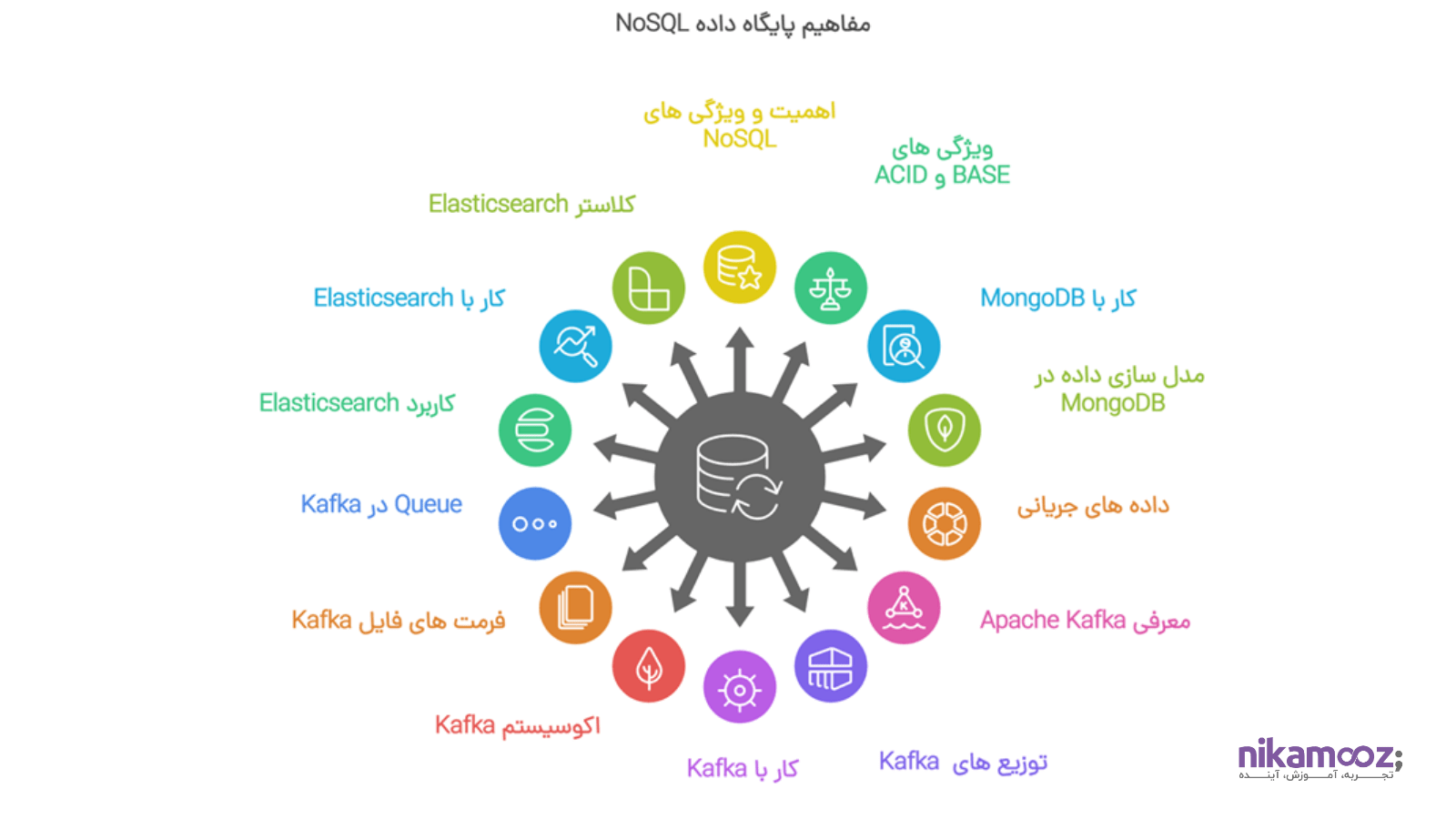
4-پایگاه داده ها و پلتفرم های NoSQL و Stream Storage
این فصل بر تنوع و اهمیت پایگاههای داده NoSQL تمرکز دارد، ویژگیهای آنها را در مقابل مدلهای سنتی ACID بررسی کرده و مفاهیمی مانند BASE را توضیح میدهد. بخش عملی شامل کار با پایگاه داده MongoDB و اصول مدلسازی داده در آن است. در ادامه، مبحث دادههای جریانی (Stream Data) و چالشهای آن معرفی میشود و پلتفرم Apache Kafka به عنوان ابزار اصلی ذخیرهسازی جریانی، ساختار، کاربردها و مؤلفههای آن (مانند Kafka Connect) مورد بررسی قرار میگیرد. در نهایت، معماری و نحوه کار با Elasticsearch برای مدیریت و جستجوی دادههای حجیم به عنوان یک ابزار قدرتمند تحلیلی، آموزش داده میشود.
- اهمیت، ویژگی ها و علت تنوع پایگاه داده های NoSQL
- ویژگی های ACID و BASE در پایگاه داده های NoSQL
- کار با MongoDB
- مدل سازی داده در مانگو دی بی و نکات مدل سازی
- داده های جریانی، ویژگی ها و چالش های آن
- معرفی Apache Kafka و کاربرد و ویژگی های آن
- توزیع های مختلف کافکا و پلتفرم های سازگار با Protocol کافکا
- کار با کافکا و کامپوننت های کافکا مانند Kafka Connect
- اکوسیستم کافکا و انجام سناریو های مختلف ذخیره و بازیابی داده در کافکا
- فرمت های مختلف فایل برای کافکا
- Queue در کافکا
- کاربرد Elasticsearch و معماری آن
- کار با Elasticsearch
- کلاستر Elasticsearch و ساختار آن
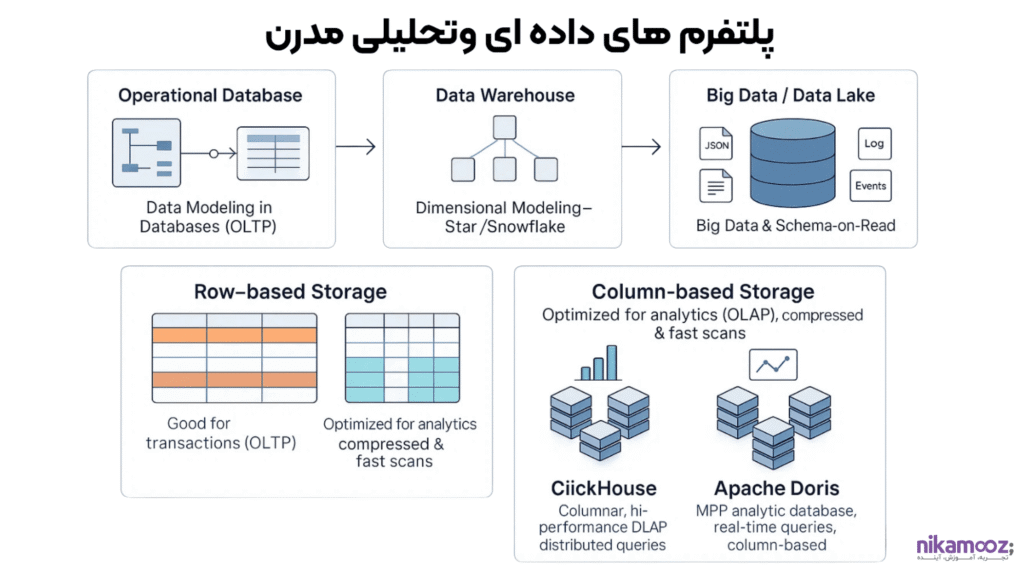
5-پلتفرم های داده ای و تحلیلی مدرن
این بخش به معرفی و کاربرد پلتفرمهای تحلیلی و انبارهای داده مدرن که برای پردازش و تحلیل کارآمد دادههای حجیم طراحی شدهاند، میپردازد. ابتدا مفاهیم مدلسازی داده در انبار داده و تفاوتهای کلیدی بین ذخیرهسازی Row-base و Column-base که سرعت کوئریها را تحت تأثیر قرار میدهند، مرور میشوند. سپس، شرکتکنندگان با پلتفرمهای ستونی با کارایی بالا مانند ClickHouse و Apache Doris آشنا میشوند و نحوه کار، ویژگیها و مزایای استفاده از آنها در محیطهای تحلیلی پیچیده برای ارائه گزارشگیریهای سریع و پاسخگویی به کوئریهای تحلیلی را فرا میگیرند.
- مدل سازی داده در دیتابیس، انبار داده و بیگ دیتا
- تفاوت ذخیره سازی Row-base و Column-base
- کار با ClickHouse و ویژگی های کلیک هاس
- کار با Doris Apache و ویژگی های دوریس
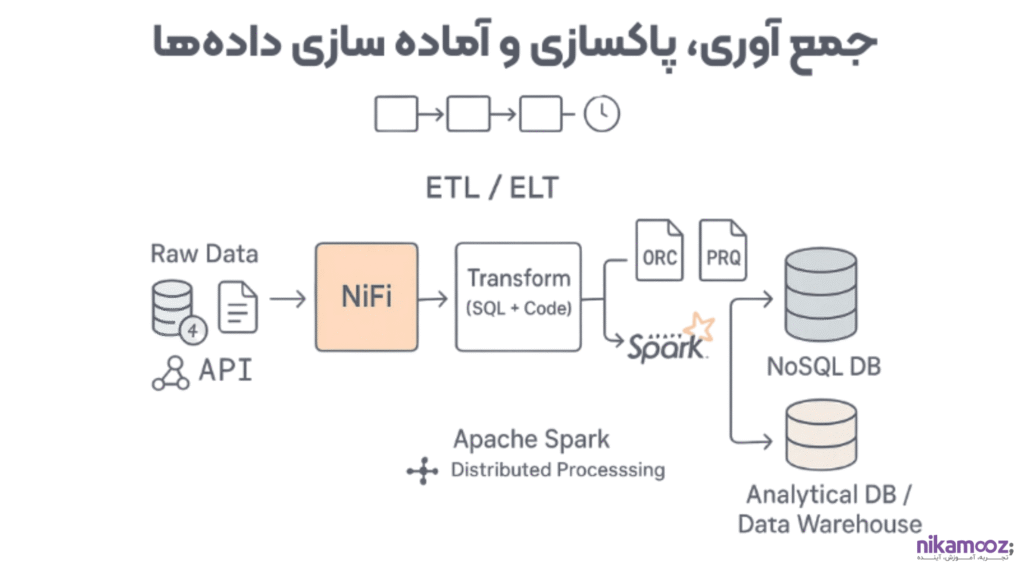
6-جمع آوری، پاکسازی و آماده سازی داده ها
این فصل هسته اصلی کار یک مهندس داده را تشکیل میدهد و فرآیندهای حیاتی ETL و ELT و اهمیت کیفیت داده را پوشش میدهد. این بخش بر روی پیادهسازی عملی سناریوهای آمادهسازی دادهها با استفاده از دستورات SQL و یک زبان برنامهنویسی تمرکز میکند. همچنین، استفاده از ابزارهای خاصی مانند Apache NiFi برای طراحی Data Flowهای جمعآوری داده و Apache Spark به عنوان یک فریمورک پردازش توزیعشده مقیاسپذیر برای اجرای سناریوهای مختلف Spark SQL و خواندن/نوشتن در منابع دادهای NoSQL و تحلیلی آموزش داده میشود. در پایان، مفاهیم مربوط به فرمتهای بهینه ذخیرهسازی مانند ORC و Parquet و روشهای Scheduling تسکهای دادهای با استفاده از ابزارهایی مانند Airflow بررسی خواهند شد.
- ETL و ELT
- کیفیت داده و معیار های آن
- پیاده سازی سناریو های مختلف آماده سازی داده به کمک یک زبان برنامه نویسی و دستورات SQL
- مقیاس پذیری درلایه پردازش و استفاده از روش های پردازش توزیع شده
- استفاده از Apache NiFi برای طراحی Data Flow های جمع آوری داده
- انجام سناریو های متنوع Ingestion در NiFi به پایگاه داده های NOSQL و تحلیلی
- مروری بر Apache Spark و قابلیت های آن
- انجام سناریو های مختلف پردازش داده در Spark SQL
- بررسی فرمت فایل های ORC و Parquet و مزایا و معایب آنها
- خواندن و نوشتن در منابع داده ای NoSQL و تحلیلی با آپاچی اسپارک
- روش های Scheduling تسک ها
- استفاده از Airflow برای Scheduling