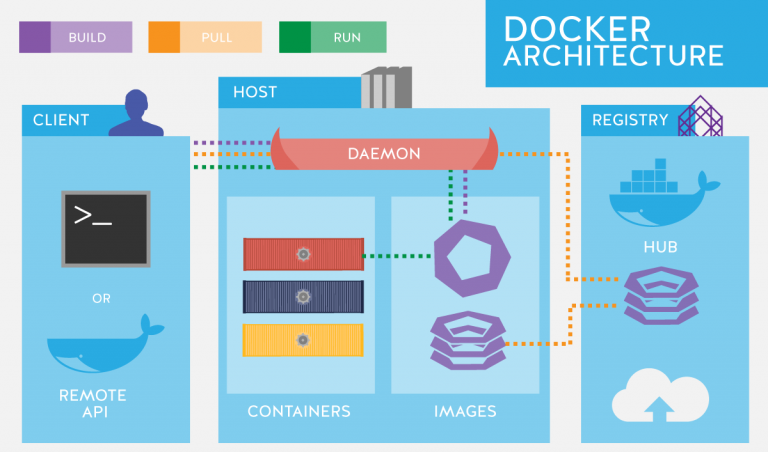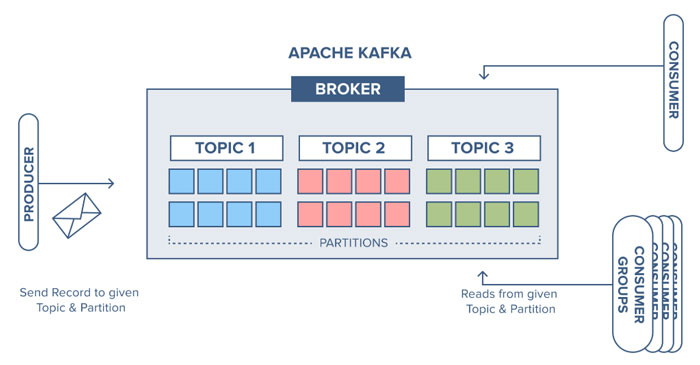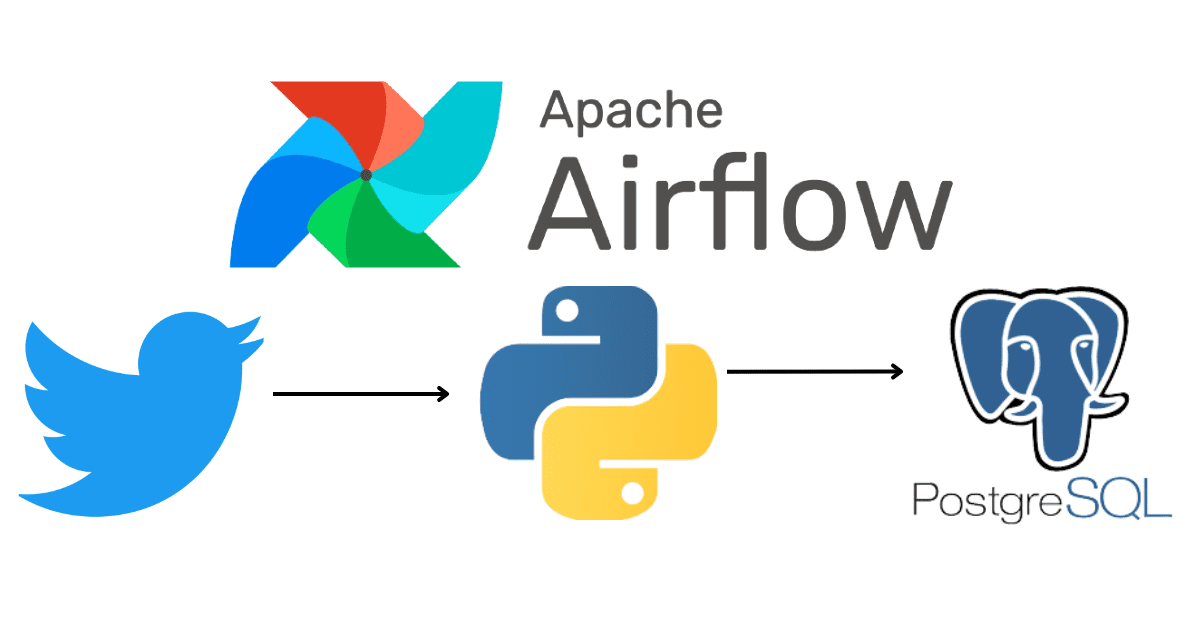










مهندسی داده به عنوان یک جایگاه شغلی نوظهور در حوزه پردازش داده، نقش مهمی را در سامانه های اطلاعاتی مقیاس پذیر روز دنیا ایفا می کند. این جایگاه که در حال حاضر در ایران بیشتر مورد نیاز شرکت های بزرگ است، در چند سال آینده، به یک بازیگر اصلی تمامی سامانه های اطلاعاتی بومی تبدیل خواهد شد.
مهندسی داده، مهندسی سامانه های مقیاس پذیر اطلاعاتی است و بنابراین به دانش مناسبی از حوزه پردازش دادههای کلان و طراحی سیستم های توزیع شده نیاز دارد. در دوره مبانی مهندسی داده، به مروری بر فناوریها و ابزارهای این حوزه از طریق انجام مثالهای عملی خواهیم پرداخت.
۱. بررسی اکوسیستم و تاریخچه پروژههای کلانداده
۲. بیان جایگاه و ضرورت مهندسی داده به عنوان پایه و اساس سامانههای مقیاسپذیر پردازش داده
۳. مهندس داده و چالش های پیش رو آن
۴. بررسی شباهتها و تفاوتهای مهندسی داده با علم داده
۵. بررسی جایگاه مهندس داده