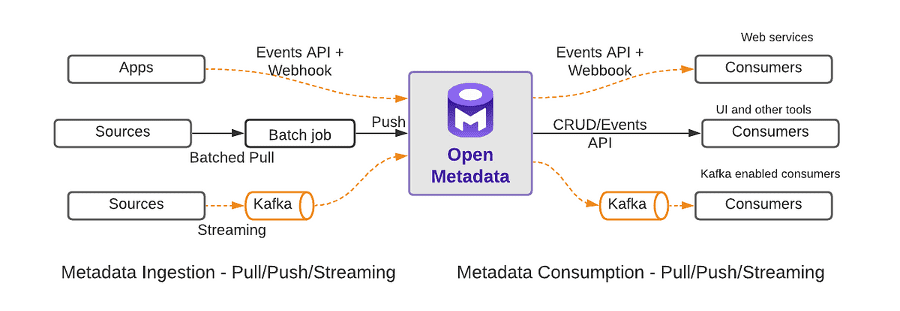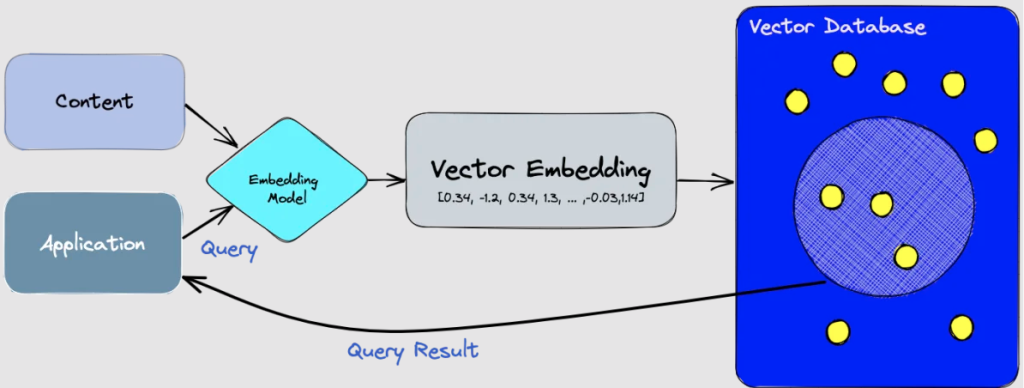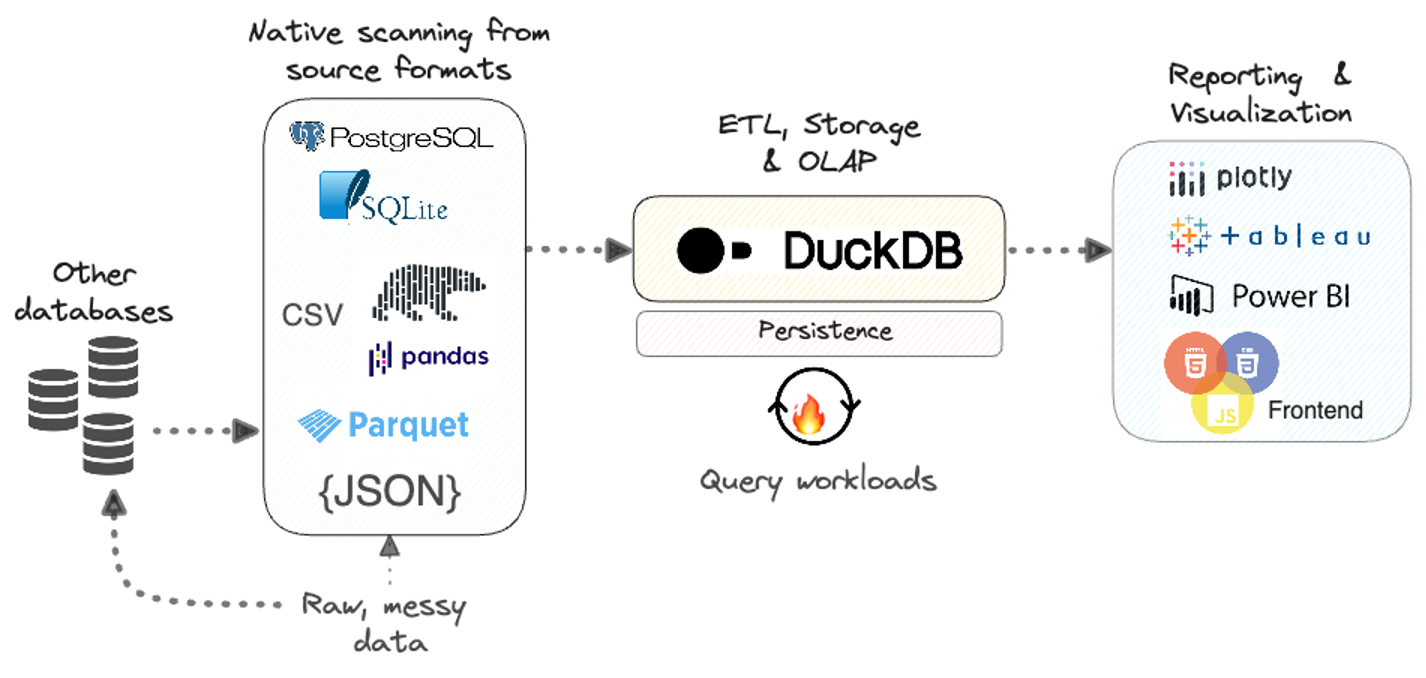









در بسیاری از کاربردهای نوین پردازش اطلاعات، علاوه بر نیاز به ذخیره اطلاعات به صورت خام، باید بتوانیم ساختاری برای ذخیره این دادهها به کار بریم که در صورت نیاز به جستجوی اطلاعات در این دادهها، امکان جستجوی موثر و سریع آنها نیز فراهم باشد.
در این راستا در یک دهه گذشته، ابتدا مفهوم دریاچه داده ایجاد شد که مکانیزمهای اولیه برای ذخیره دادههای خام را فراهم میکرد اما استفاده موثر از دادههای خام نیازمند مکانیزمهای پیشرفته بود. در چند سال اخیر با ایده جدید Lakehouse که ترکیب Warehouse با Data Lake بود، این فضا به کلی تغییر کرد و امروزه برای ساخت دریاچههای داده، معمولا از Lakehouse استفاده میکنیم.
در این دوره با مرور این مفاهیم و سه ساختار اصلی ذخیره دادهها در این حوزه یعنی Deltalake, IceBerge و Hudi به طراحی یک Lakehouse به کمک Minio و Iceberge خواهیم پرداخت
Minio به عنوان یک فضای ذخیره سازی توزیع شده و مبتنی بر پروتکل S3 آمازون عمل خواهد کرد و آپاچی آیسبرگ، به ما امکان ذخیره و تحلیل دادههای خام را خواهد داد.
آشنایی با این مفاهیم به شما کمک میکند تا بتوانید یک سیستم دریاچه داده موثر و قابل اطمینان با استفاده از Minio و Apache Iceberg ایجاد کرده و دادههای خام را به صورت موثر مدیریت کنید.